There are some pretty interesting and helpful blog posts available at the moment and we would like to share some information regarding our new release of Performance Analyzer.You can find here an interesting post from Frank Denneman or just scroll down for more information.
Some changes are made in ESXi 6.5 with regards to sizing and configuration of the virtual NUMA topology of a VM. A big step forward in improving performance is the decoupling of Cores per Socket setting from the virtual NUMA topology sizing.
Important information from Frank Dennemann´s post!
Understanding elemental behavior is crucial for building a stable, consistent and proper performing infrastructure. If you are using VMs with a non-default Cores per Socket setting and planning to upgrade to ESXi 6.5, please read this article, as you might want to set a Host advanced settings before migrating VMs between ESXi hosts. More details about this setting is located at the end of the article, but let’s start by understanding how the CPU setting Cores per Socket impacts the sizing of the virtual NUMA topology.
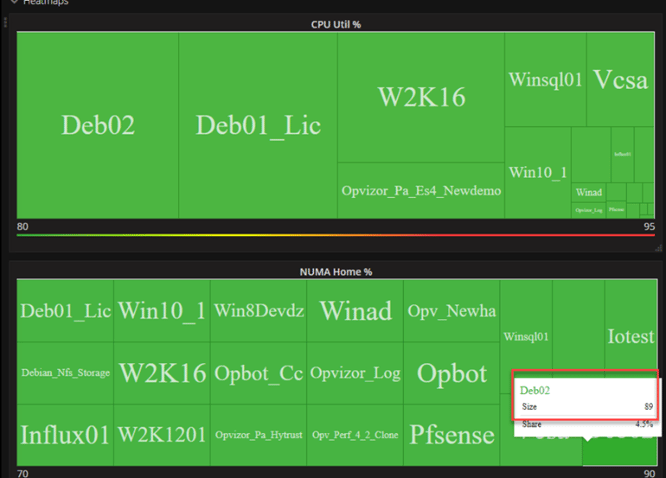
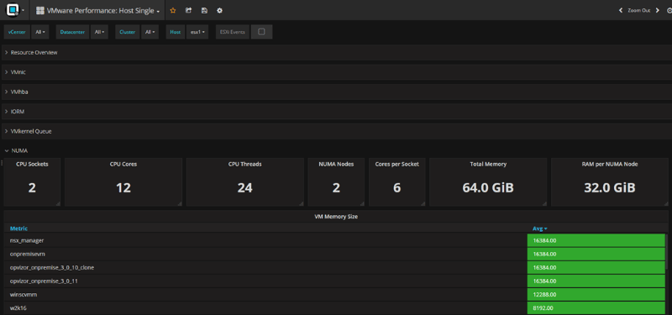
To get an overview of your NUMA configuration, download and setup Performance Analyzer and check the VMware Performance: Host Single dashboard:
Cores per Socket
By default, a vCPU is a virtual CPU package that contains a single core and occupies a single socket. The setting Cores per Socket controls this behavior; by default, this setting is set to 1. Every time you add another vCPU to the VM another virtual CPU package is added, and as follows the socket count increases.
Virtual NUMA Topology
Since vSphere 5.0 the VMkernel exposes a virtual NUMA topology, improving performance by facilitating NUMA information to guest operating systems and applications. By default the virtual NUMA topology is exposed to the VM if two conditions are met:
- The VM contains 9 or more vCPUs
- The vCPU count exceeds the core count* of the physical NUMA node.
* When using the advanced setting “numa.vcpu.preferHT=TRUE”, SMT threads are counted instead of cores to determine scheduling options.
Using the following one-liner we can explore the NUMA configuration of active virtual machines on an ESXi host:
vmdumper -l | cut -d / -f 2-5 | while read path; do egrep -oi "DICT.*(displayname.*|numa.*|cores.*|vcpu.*|memsize.*|affinity.*)= .*|numa:.*|numaHost:.*" "/$path/vmware.log"; echo -e; done
When using this one-liner after powering-on a 10-vCPU virtual machine on the dual E5-2630 v4 ESXi 6.0 host the following NUMA configuration is shown:
Photo courtesy of Frank Denneman
The VM is configured with 10 vCPUs (numvcpus). The cupid.coresPerSocket = 1 indicates that it’s configured with one core per socket. The last entry summarizes the virtual NUMA topology of the virtual machine. The constructs virtual nodes and physical domains will be covered later in detail.
All 10 virtual sockets are grouped into a single physical domain, which means that the vCPUs will be scheduled in a single physical CPU package that typically is similar to a single NUMA node. To match the physical placement, a single virtual NUMA node is exposed to the virtual machine.
Microsoft Sysinternals tool CoreInfo exposes the CPU architecture in the virtual machine with great detail. (Linux machines contain the command numactl – – hardware and use lstopo -s to determine cache configuration). Each socket is listed and with each logical processor a cache map is displayed. Keep the cache map in mind when we start to consolidate multiple vCPUs into sockets.

Photo courtesy of Frank Denneman
Virtual NUMA topology
The vCPU count of the VM is increased to 16 vCPUs; as a consequence, this configuration exceeds the physical core count. MS Coreinfo provides the following insight:
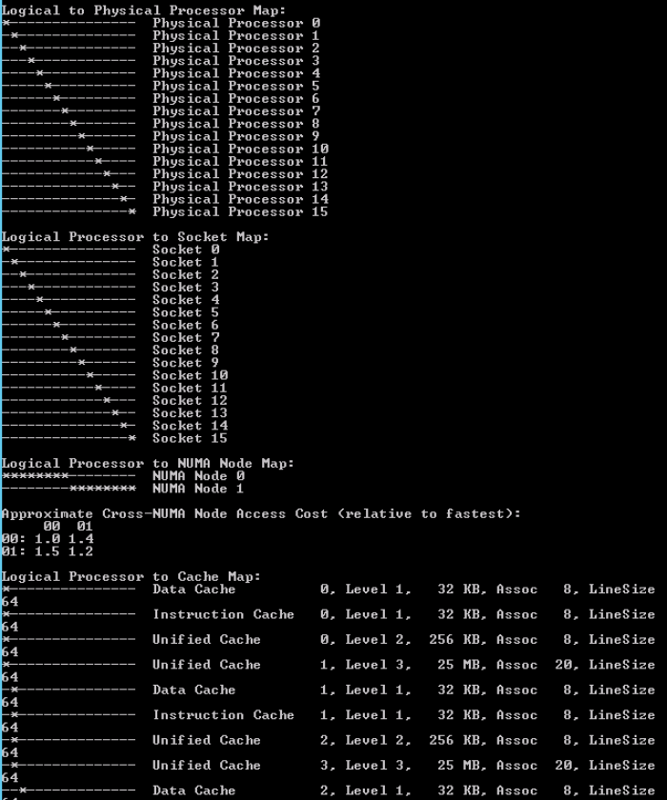
Photo courtesy of Frank Denneman
Coreinfo uses an asterisk to represent the mapping of the logical processor to socket map and NUMA Node Map. In this configuration the logical processors in Socket 0 to Socket 7 belong to NUMA Node 0, the CPUs in Socket 8 to Socket 15 belong to NUMA 1. Please note that this screenshot does not contain the entire logical processor cache map overview.
Running the vmdumper one-liner on the ESXi host, the following is displayed:
Photo courtesy of Frank Denneman
In the previous example in which the VM was configured with 10 vCPUs, the numa.autosize.vcpu.maxPerVirtualNode = “10”, in this scenario, the 16 vCPU VM, has a numa.autosize.vcpu.maxPerVirtualNode = “8”.
The VMkernel symmetrically distributes the 16 vCPUs across multiple virtual NUMA Nodes. It attempts to fit as much vCPUs into the minimum number of virtual NUMA nodes, hence the distribution of 8 vCPU per virtual node. It actually states this “Exposing multicore topology with cpuid.coresPerSocket = 8 is suggested for best performance”.
Virtual Proximity Domains and Physical Proximity Domains
A virtual NUMA topology consists of two elements, the Virtual Proximity Domains (VPD) and the Physical Proximity Domains (PPD). The VPD is the construct what is exposed to the virtual machine, the PPD is the construct used by NUMA for placement (Initial placement and load-balancing).
The PPD auto sizes to the optimal number of vCPUs per physical CPU Package based on the core count of the CPU package. Unless the setting Cores per Socket within a VM configuration is used. In ESXi 6.0 the configuration of Cores per Socket dictates the size of the PPD, up to the point where the vCPU count is equal to the number of cores in the physical CPU package. In other words, a PPD can never span multiple physical CPU packages.
Photo courtesy of Frank Denneman
The best way to perceive a proximity domain is to compare it to a VM to host affinity group, but in this context, it is there to group vCPU to CPU Package resources. The PPD acts like an affinity of a group of vCPUs to all the CPUs of a CPU package. A proximity group is not a construct that is scheduled by itself. It does not determine whether a vCPU gets scheduled on a physical resource. It just makes sure that this particular group of vCPUs consumes the available resources on that particular CPU package.
A VPD is the construct that exposes the virtual NUMA topology to the virtual machine. The number of VPDs depends on the number of vCPUs and the physical core count or the use of Cores per Socket setting. By default, the VPD aligns with the PPD. If a VM is created with 16 vCPUs on the test server two PPD’s are created. These PPD allow the VPDs and its vCPUs to map and consume physical 8 cores of the CPU package.
Photo courtesy of Frank Denneman
If the default vCPU settings are used, each vCPU is placed in its own CPU socket (Cores per Socket = 1). In the diagram, the dark blue boxes on top of the VPD represent the virtual sockets, while the light blue boxes represent vCPUs.
The VPD to PPD alignment can be overruled if a non-default Cores per Socket setting is used. A VPD spans multiple PPDs if the number of the vCPUs and the Cores per Socket configuration exceeds the physical core count of a CPU package.
For example, a virtual machine with 40 vCPUs and 20 Cores per Socket configuration on a host with four CPU packages containing each 10 cores, creates a topology of 2 VPD’s that each contains 20 vCPUs, but spans 4 PPDs.

Photo courtesy of Frank Denneman
The Cores per Socket configuration overwrites the default VPD configuration and this can lead to suboptimal configurations if the physical layout is not taken into account correctly.
Specifically, spanning VPDs across PPDs is something that should be avoided at all times. This configuration can render most CPU optimizations inside the guest OS and application completely useless. For example, OS and applications potentially encounter remote memory access latencies while expecting local memory latencies after optimizing thread placements.
It’s recommended to configure the VMs Cores per Socket to align with the physical boundaries of the CPU package.
ESXi 6.5 Cores per Socket behavior
In ESXi 6.5 the CPU scheduler has got some interesting changes. Expect an interesting blog post of Mark Achtemichuk (VMware performance team) soon. One of the changes in ESXi 6.5 is the decoupling of Cores per Socket configuration and VPD creation to further optimize virtual NUMA topology.
Up to ESXi 6.0, if a virtual machine is created with 16 CPUs and 2 Cores per Socket, 8 PPDs are created and 8 VPDs are exposed to the virtual machine.
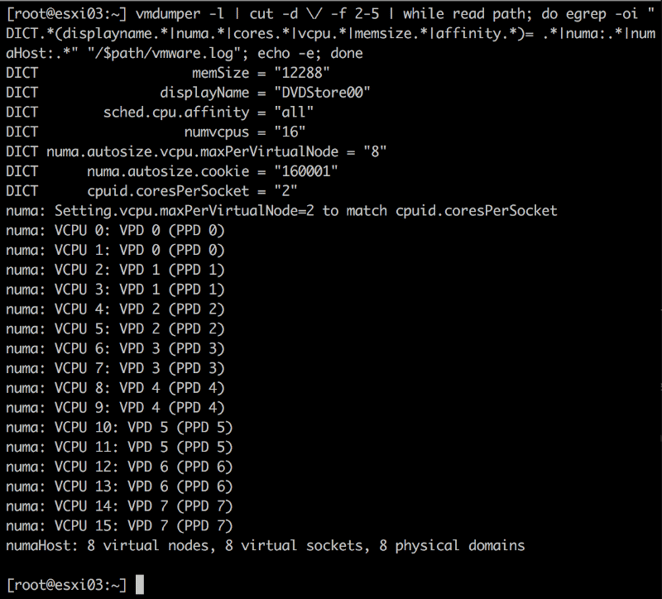
Photo courtesy of Frank Denneman
The problem with this configuration is that it the virtual NUMA topology does not represent the physical NUMA topology correctly.
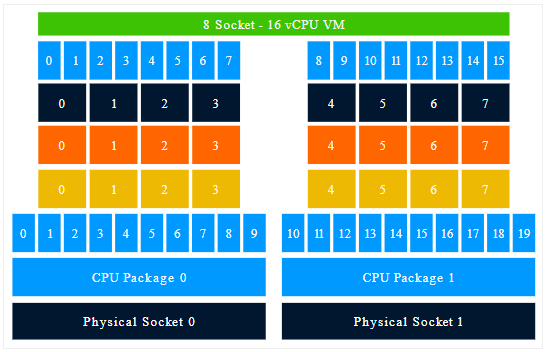
Photo courtesy of Frank Denneman
The guest OS is presented with 16 CPUs distributed across 8 sockets. Each pair of CPUs has its own cache and its own local memory. The operating system considers the memory addresses from the other CPU pairs to be remote. The OS has to deal with 8 small chunks of memory spaces and optimize its cache management and memory placement based on the NUMA scheduling optimizations. Where in truth, the 16 vCPUs are distributed across 2 physical nodes, thus 8 vCPUs share the same L3 cache and have access to the physical memory pool. From a cache and memory-centric perspective it looks more like this:
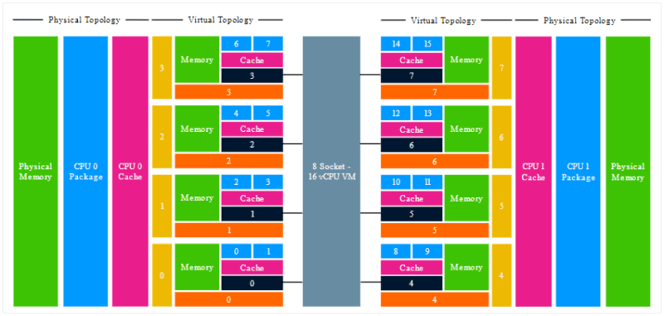
Photo courtesy of Frank Denneman
CoreInfo output of the CPU configuration of the virtual machine:
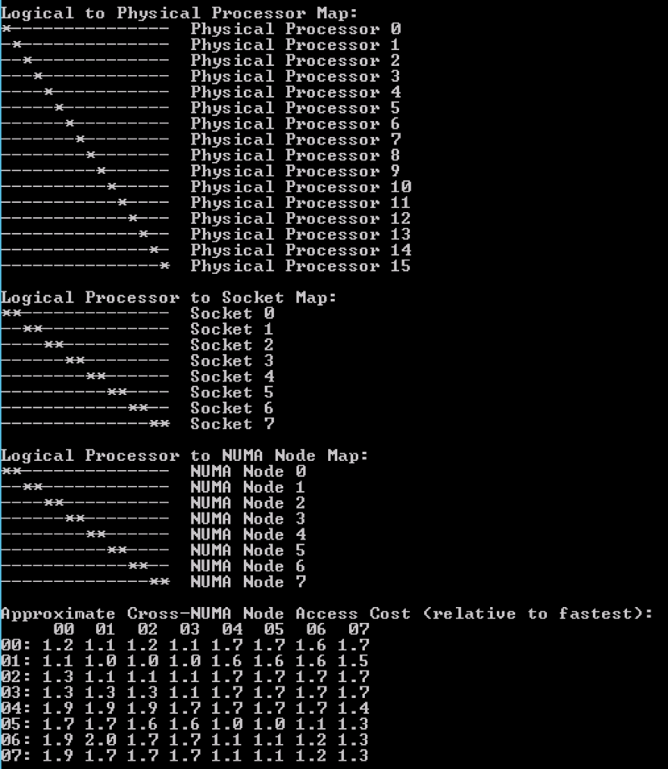
Photo courtesy of Frank Denneman
To avoid “fragmentation” of local memory, the behavior of VPDs and it’s relation to the Cores per Socket setting has changed. In ESXi 6.5 the size of the VPD is dependent on the number of cores in the CPU package. This results in a virtual NUMA topology of VPDs and PPDs that attempt to resemble the physical NUMA topology as much as possible.
Using the same example of 16 vCPU, 2 Cores per Socket, on a dual Intel Xeon E5-2630 v4 (20 cores in total), the vmdumper one-liner shows the following output in ESXi 6.5:
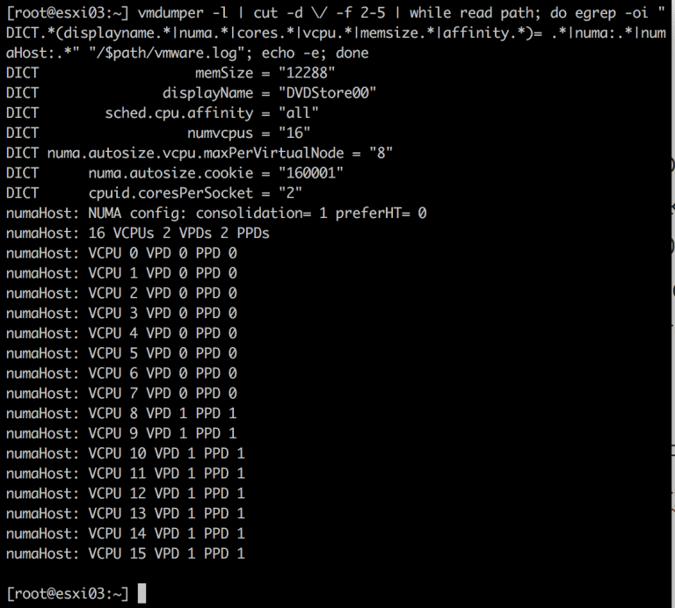
Photo courtesy of Frank Denneman
As a result of having only two physical NUMA nodes, only two PPDs and VPDs are created. Please note that the Cores per Socket setting has not changed, thus multiple sockets are created in a single VPD.
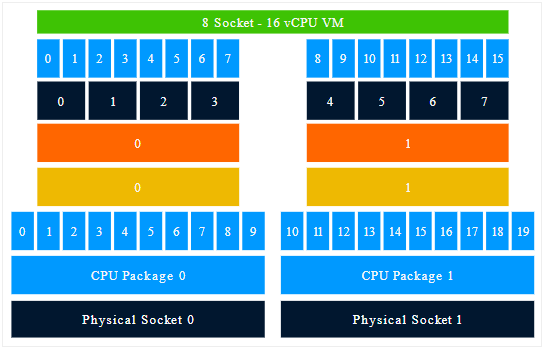
Photo courtesy of Frank Denneman
A new line appears in ESXi 6.5; “NUMA config: consolidation =1”, indicating that the vCPUs will be consolidated into the least amount of proximity domains as possible. In this example, the 16 vCPUs can be distributed across 2 NUMA nodes, thus 2 PPDs and VPDs are created. Each VPD exposes a single memory address space that correlates with the characteristics of the physical machine.
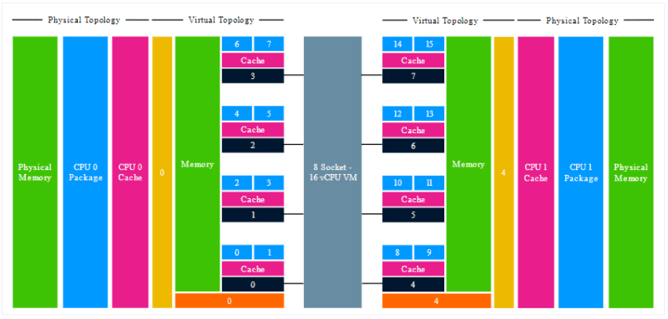
Photo courtesy of Frank Denneman
The Windows 2012 guest operating system running inside the virtual machine detects two NUMA nodes. The CPU view of the task managers shows the following configuration:
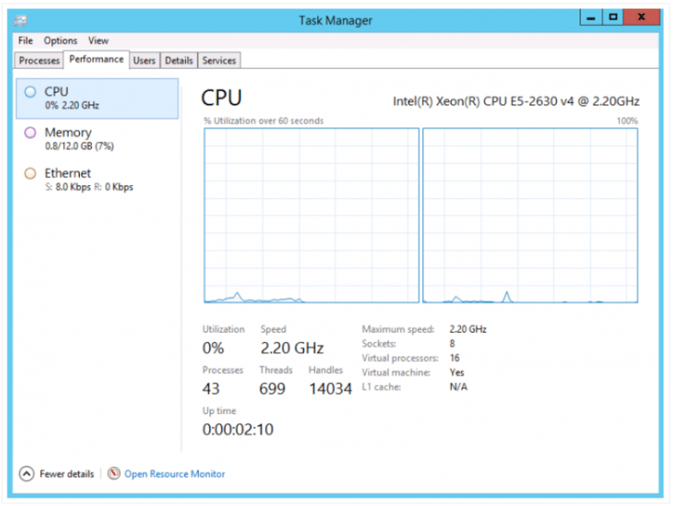
Photo courtesy of Frank Denneman
The NUMA node view is selected and at the bottom right of the screen, it shows that virtual machine contains 8 sockets and 16 virtual CPUs. CoreInfo provides the following information:
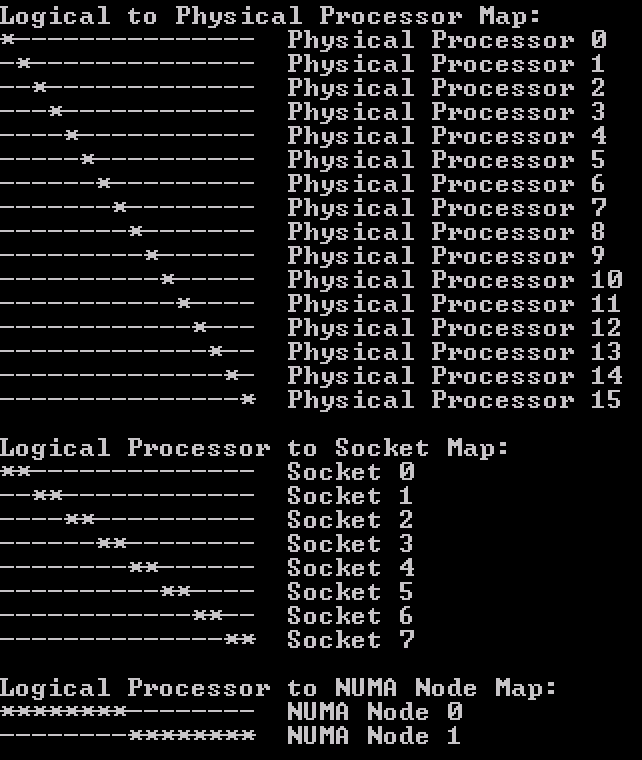
Photo courtesy of Frank Denneman
With this new optimization, the virtual NUMA topology corresponds more to the actual physical NUMA topology, allowing the operating system to correctly optimize its processes for correct local and remote memory access.
Guest OS NUMA optimization
Modern applications and operating systems manage memory access based on NUMA nodes (memory access latency) and cache structures (sharing of data).
Unfortunately most applications, even the ones that are highly optimized for SMP, do not balance the workload perfectly across NUMA nodes. Modern operating systems apply a first-touch-allocation policy, which means that when an application requests memory, the virtual address is not mapped to any physical memory. When the application accesses the memory, the OS typically attempts to allocate it on the local or specified NUMA if possible.
In an ideal world, the thread that accessed or created the memory first is the thread that processes it. Unfortunately, many applications use single threads to create something, but multiple threads distributed across multiple sockets access the data intensively in the future.
Please take this into account when configuring the virtual machine and especially when configuring Cores per Socket. The new optimization will help to overcome some of these inefficiencies created in the operating system.
However, sometimes it’s required to configure the virtual machine with a deviating Cores per Socket setting, due to licensing constraints for example.
If you are required to set Cores per Socket and you want to optimize guest operating system memory behavior any further, then configure the Cores per Socket to align with the physical characteristics of the CPU package.
As demonstrated the new virtual NUMA topology optimizes the memory address space, providing a bigger more uniform memory slice that aligns better with the physical characteristics of the system. One element has not been thoroughly addressed and that is cache address space created by a virtual socket. As presented by CoreInfo, each virtual socket advertises its own L3 cache.
In the scenario of the 16 vCPU VM on the test system, configuring it with 8 Cores per socket, this configuration resembles both the memory and the cache address space of the physical CPU package the most.
Coreinfo shows the 16 vCPUs distributed symmetrically across two NUMA nodes and two sockets. Each socket contains 8 CPUs that share L3 cache, similar to the physical world.
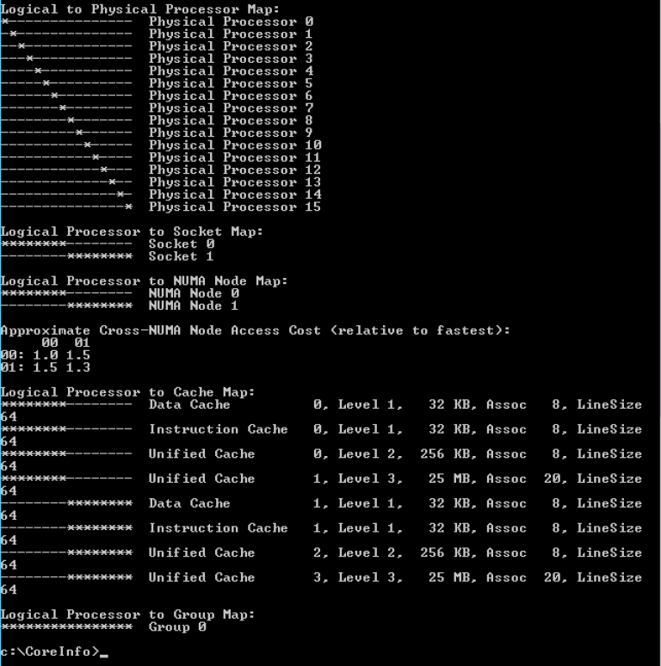
Photo courtesy of Frank Denneman
Word of caution!
Migrating VMs configured with Cores per Socket from older ESXi versions to ESXi 6.5 hosts can create PSODs and/or VM Panic
Unfortunately, there are some virtual NUMA topology configurations that cannot be consolidated properly by the GA release of ESXi 6.5 when vMotioning a VM from an older ESXi version.
If you have VMs configured with a non-default Cores per Socket setting or you have set the advanced parameter numa.autosize.once to False, enable the following advanced host configuration on the ESXi 6.5 host:
Numa.FollowCoresPerSocket = 1
A reboot of the host is not necessary! This setting makes ESXi 6.5 behave as ESXi 6.0 when creating the virtual NUMA topology. That means that the Cores per Socket setting determines the VPD sizing.
There have been some cases reported where the ESXi 6.5 crashes (PSOD). Test it in your lab and if your VM configuration triggers the error set the FollowCoresPerSocket setting as an advanced configuration.
Knowledge base article 2147958 has more information. I’ve been told that the CPU team is working on a permanent fix, I do not have insights when this fix will be released!
Thanks again to Frank!
Sneak Peak Performance Analyzer
There is a neat functionality we´re working on and you can expect that this quarter. NUMA Home Node percentage. That value is extremely important because it indicates what percentage of memory access is using the optimized CPU-Memory path (NUMA Channel intern). A low percentage should let you worry and 100% is great.